2021-05-07
10:15 - 11:15
Visual Computing Forum
Julius Parulek is a software developer and data analyst in Equinor ASA, Norway. He holds M.Sc. in computer science (2004) and PhD in applied informatics (2008). From 2010 until 2018 he was associated with UiB (Post-doc, adjunct associate prof.,) in the Visualization team. His research topics cover a broad range of fields, which includes history matching, data analysis, visualization, machine learning as well as software development and GPU computing.
Abstract:
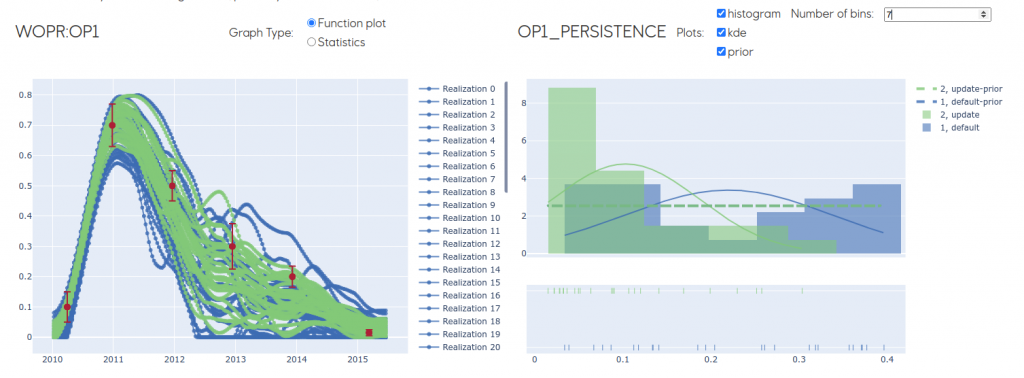
Obtaining accurate models of a real-world phenomenon is a challenging task. The models often come with many uncertainties spawning different versions of how such models could look like. In history matching we tend to generate hundreds of models, where observed / measured data helps to narrow down or improve the models in such a way that they better approximate reality.
When models are composed of thousands of input parameters producings tens of thousands vectors of simulation data, visualization is used to navigate through the data space — mainly to reason about how to modify the input parameters and the observation uncertainty.
In this talk I will start by briefly introducing the ensemble Kalman filter and the workflow we employ to improve the models based on the real-world observations. I will demonstrate the approach on examples from updating a reservoir model, which poses an extra challenge due they can not be easily observed. Moreover, I will present the current visualization techniques that assist us to analyze the results and introduce the future plans.